CDK for Terraform (CDKTF) on AWS

Table of Contents
- Introduction
- Step 1: Required Prerequisites
- Step 2: Initializing First CDKTF Project using Python Template
- Step 3: Configuring an S3 Remote Backend
- Step 4: Learn How to Use Construct Hub and AWS Provider Submodules
- Step 5: Deploying a Lambda Function URL using CDKTF
- Conclusion
Sept 27th, 2022
How to Configure an S3 Remote Backend and Deploy a Lambda Function URL using Python on Ubuntu 20.04 LTS
Introduction
After two years of collaboration between AWS and HashiCorp and on the 9th of August, 2022, AWS announced the general availability of CDK for Terraform on AWS. As the CDKTF framework finally saw the light of day, the news triggered lots excitement among the community. The CDKTF framework is a new open-source project that enables developers to use their favorite programming languages to define and provision cloud infrastructure resources on AWS. Under the hood, it converts the programming language definitions into Terraform configuration files and uses Terraform to provision the resources.
“Learning is no longer a stage of life; it’s a lifelong journey” - Andy Bird
It’s often said that the best way to learn something new is to do it, and the first milestone in learning is often the hardest. However, with the right guidance, you can overcome the challenges and achieve your goals. My objective in this article is to guide you through the process of installing, configuring, and deploying your first AWS resource using CDKTF on AWS. In addition, I will also show you how to use the Construct Hub documentations to deploy your own AWS resources.
The tutorial should be easy to follow and understand for beginners and intermediate users. The tutorial is devoted to developers with adequate AWS, Terraform and Python knowledge but who are unsure of how and where to begin their CDKTF learning.
The main topics covered in this tutorial are:
- Proper installation and configuration of all required prerequisites.
- Installing and configuring CDKTF.
- Initializing first CDKTF project using Python template and local backend.
- Deploying a S3 bucket and DynamoDB table and configuring an S3 remote backend.
- Learning how to read/use AWS Provider Submodules and Construct Hub documentations
- Provisioning an S3 Bucket using CDKTF
- Provisioning an IAM role and Lambda Function URL using CDKTF
This tutorial is also available on my GitHub - CDKTF-Tutorial repo. By the end of this tutorial, you shall be comfortable deploying AWS resources using the CDKTF framework. I will pass you the learning baton and you can take it from there. Enough said, let’s get started.
Step 1: Required Prerequisites
To complete this tutorial successfully, we should install and configure the following prerequisites properly. To set you up for success, I have to ensure you have the following prerequisites installed and configured properly:
- AWS CLI version 2:
- Follow AWS Prerequisites to use the AWS CLI version 2 documentation for all required prerequisites.
- Follow Installing or updating the latest version of the AWS CLI document to install the AWS CLI v2 as per your local device architecture. In my case, it’s an Ubuntu 20.04 LTS OS running on a Linux x86 (64-bit) architecture.
- Lastly, follow the Configuration basics - Profiles document to configure the AWS CLI v2 and create a
named profile(name it CDKFT as shown below). We will use the named profile to configure AWS Provider credentials later on.
aws configure --profile CDKTF
Note: the profile name does not have to be CDKTF, you can name it however you like. However, I will be using CDKTF in this tutorial.
- Terraform (version v1.0+ as per Terraform’s recommendation).
- Node.js and npm v16+:
- Follow NodeSource Node.js Binary Distributions to install Node.js v16.x for Ubuntu (the installation includes npm). For other operating systems and architectures, refer to Node.js official page. Once you have Node.js installed, make sure it’s version 16.x by running the below command:
node -v
- Python 3.7+: Ubuntu 20.04 LTS distribution comes with Python 3.8.2 pre-installed by default. Run the below command to confirm:
python3 --version
Additionally, we will need to make sure we have pip installed and available.
pip3 --version
Note: if
pipis unavailable, runsudo apt install python3-pipto install it as per Python documentation.
- pipenv v2021.5.29+: as of Sept 22, 2022, the latest version of
pipenvis 2022.9.20. We will usepipto installpipenv.
pip3 install pipenv
Note: if you receive a
WARNINGstatingpipenvis not installed onPATHas shown on the below image, run the below command to add it to the path:
export PATH="the-path-mentioned-in-the-warning:$PATH"
Actual example:
export PATH="/home/CDKTF/.local/bin:$PATH"
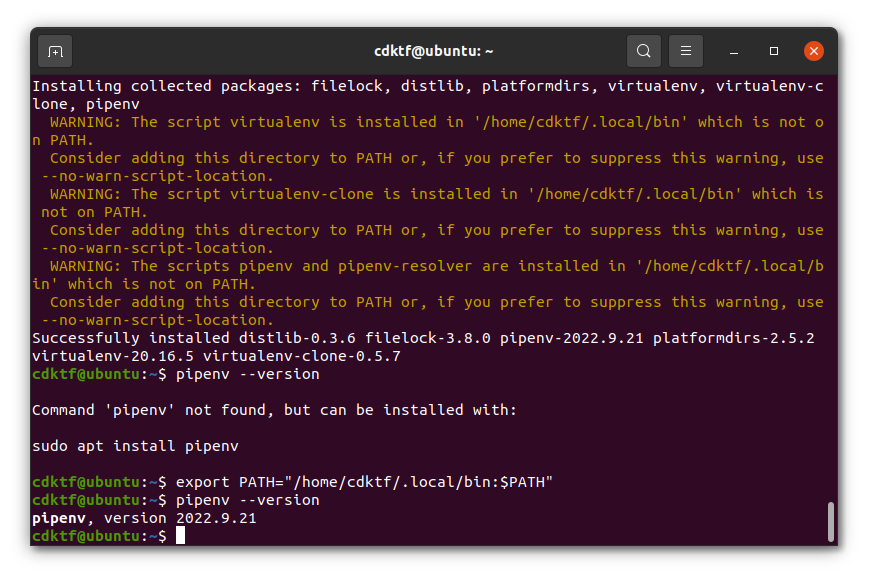
We have to confirm that pipenv is installed and available before we proceed. Run the below command to confirm:
pipenv --version
Note: it’s tempting to install
pipenvby using the package managersudo apt install pipenv, but be aware that the system repository version ofpipenvis outdated and will not work with the CDKTF framework.
- CDKFT: now, we are ready to install the latest stable release of
CDKTFusingnpm:
npm install --global cdktf-cli@latest
If you receive a permission denied error, use sudo as shown below:
sudo npm install --global cdktf-cli@latest
Let’s confirm the version:
cdktf --version
Make sure you have all required prerequisite versions installed and configured successfully as shown on the below image:
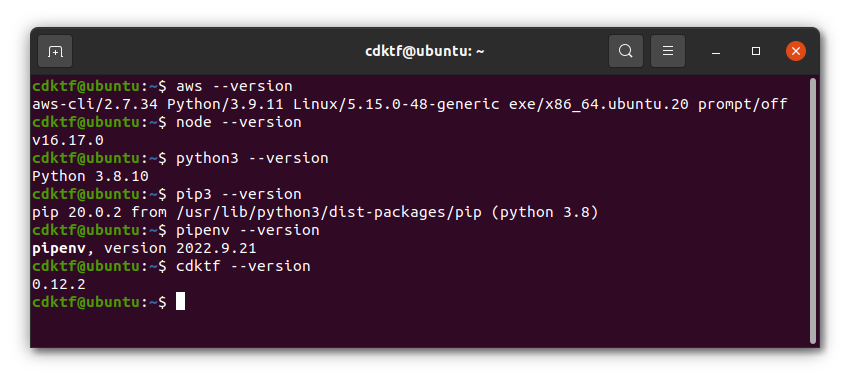
Reaching this point means you have all required prerequisites installed and configured properly. We are ready to move on to the next step. This is a milestone, so take a moment to celebrate it. You deserve it.
Step 2: Initializing the First CDKTF Project using Python Template
In this section, we will learn how to use CDKTF commands to create our first AWS CDKTF Python project. We will use the cdktf init command to create a new project in the current directory. The command also creates a cdktf.json file that contains the project configuration. The cdktf.json file contains the project name, the programming language, and the Terraform provider. The cdktf.json file is used by the cdktf command to determine the project configuration. Follow the below steps to initialize the first CDKTF project using Python template:
- Create a new directory for the project and
cdinto the directory. I will create a directory on my Desktop and name itfirst_project:
mkdir first_project && cd first_project
- Run the following command to initialize our first CDKTF project. We will be promoted to enter the following information:
A. Name of the project: leave it as first_project and hit Enter.
B. Project description: leave it as My first CDKTF project and hit Enter.
C. Send crash reports to CDKTF team. I would highly recommend you say yes to send crash reports to the CDKTF team. This will help improve the product and fix bugs.
cdktf init --template="python" --local
Note 1: we are using the
--localflag to store our Terraform state file locally. We will reconfigure the backend to S3 Remote backend in the next section.
Note 2: if you receive error
[ModuleNotFoundError: No module named 'virtualenv.seed.via_app_data'], you would need to removevirtualenvby runningsudo apt remove python3-virtualenv. We should still havevirtualenvas part of the pip packages. Runpip3 show virtualenvto confirm. If you don’t seevirtualenvin the list, runpip3 install virtualenvto install it.
- Activate the project’s virtual environment (optional but recommended):
pipenv shell
Note: the purpose of creating a virtual environment is to isolate the project and and all its packages and dependencies from the host or local device. It’s a self contained environment within the host to prevent polluting the system. It’s highly recommended to activate it to keep your host healthy and clean.
- Install AWS provider. There are multiple ways to install AWS Provider. We will use
pipenvto install the AWS provider. Run the below command to install the AWS provider:
pipenv install cdktf-cdktf-provider-aws
Note: as of the 26th of Sept, 2022, if you decide to install the AWS Provider using
cdktf provider add "aws@~>4.0", the installation will fail due to no matching distribution found for version v9.0.36. There are other methods of importing a provider but this tutorial won’t discuss to focus on simplicity.

Congratulations, you have successfully initialized your first CDKTF Python project. This is another milestone to celebrate. Get a cup of coffee ☕️ and let’s move on to the next section.
Step 3: Configuring an S3 Remote Backend
Terraform stores all managed infrastructure and configuration by default in a file named terraform.tfstate. If a local backend is configured for the project, the state file is stored in the current working directly. However, when working in a team environment to collaborate with other team members, it is important to configure a remote backend. There are several remote backend options such as, consul, etcd, gcs, http and s3. For a full list of remote backends, refer to Terraform documentation.
For this tutorial, we will configure an S3 Remote Backend which includes an S3 bucket for storing the state file and a DynamoDB table for state locking and consistency checking.
Select one of the following options to configure the S3 Remote Backend:
Option 1: Utilize an existing S3 bucket and DynamoDB to configure the S3 Remote Backend.
-
From Step 2, while we still have the virtual environment activated, let’s open the project directory using our choice of an Integrated Development Environment (IDE). In my case, I’m using Visual Studios Code which I downloaded from the
Ubuntu Software Store. Runcode .on the terminal to open the project directory via VS Code. -
Navigate to
main.pyfile and add the AWS provider construct to the imports section:
from cdktf_cdktf_provider_aws import AwsProvider
Note: the final
main.pycode will be provided at the end of this section.
- Configure the AWS provider by adding the following code to
MyStackclass:
AwsProvider(self, "AWS", region="us-east-1", profile="CDKTF")
Note: we are using the
profileattribute to specify the AWS profile to use. This is the AWS CLI profile we have previously discussed and created in the Required Prerequisites section. If you don’t have a profile created, you can remove theprofileattribute and the AWS provider will use the default profile. Or, you can use a different authentication method as per the AWS Provider documentation.
- Add
S3Backendclass to the other imported classes. The S3Backend class is employing the S3 bucket and DynamoDB table as an S3 remote backend.
from cdktf import App, TerraformStack, S3Backend
- Add the S3 Backend construct to the
main.pyfile. We will add the following S3 Backend configurations to theMyStackclass:
-
bucket- the name of the S3 bucket to store the state file. The bucket must exist and be in the same region as the stack. If the bucket doesn’t exist, the stack will fail to deploy. -
key- the name of the state file and its path. The default value isterraform.tfstate. -
encrypt- whether to encrypt the state file using server-side encryption with AWS KMS. The default value istrue. -
region- the region of the S3 bucket and DynamoDB table. The default value isus-east-1. -
dynamodb_table- the name of the DynamoDB table to use for state locking and consistency checking. The table must exist and be in the same region as the stack. If the table doesn’t exist, the stack will fail to deploy. -
profile- the AWS CLI profile to use. The default value isdefault. But, we have already configured the AWS provider to use theCDKTFprofile.
Here is how the S3 Backend construct will look like:
S3Backend(self,
bucket="cdktf-remote-backend",
key="first_project/terraform.tfstate",
encrypt=True,
region="us-east-1",
dynamodb_table="cdktf-remote-backend-lock",
profile="CDKTF",
)
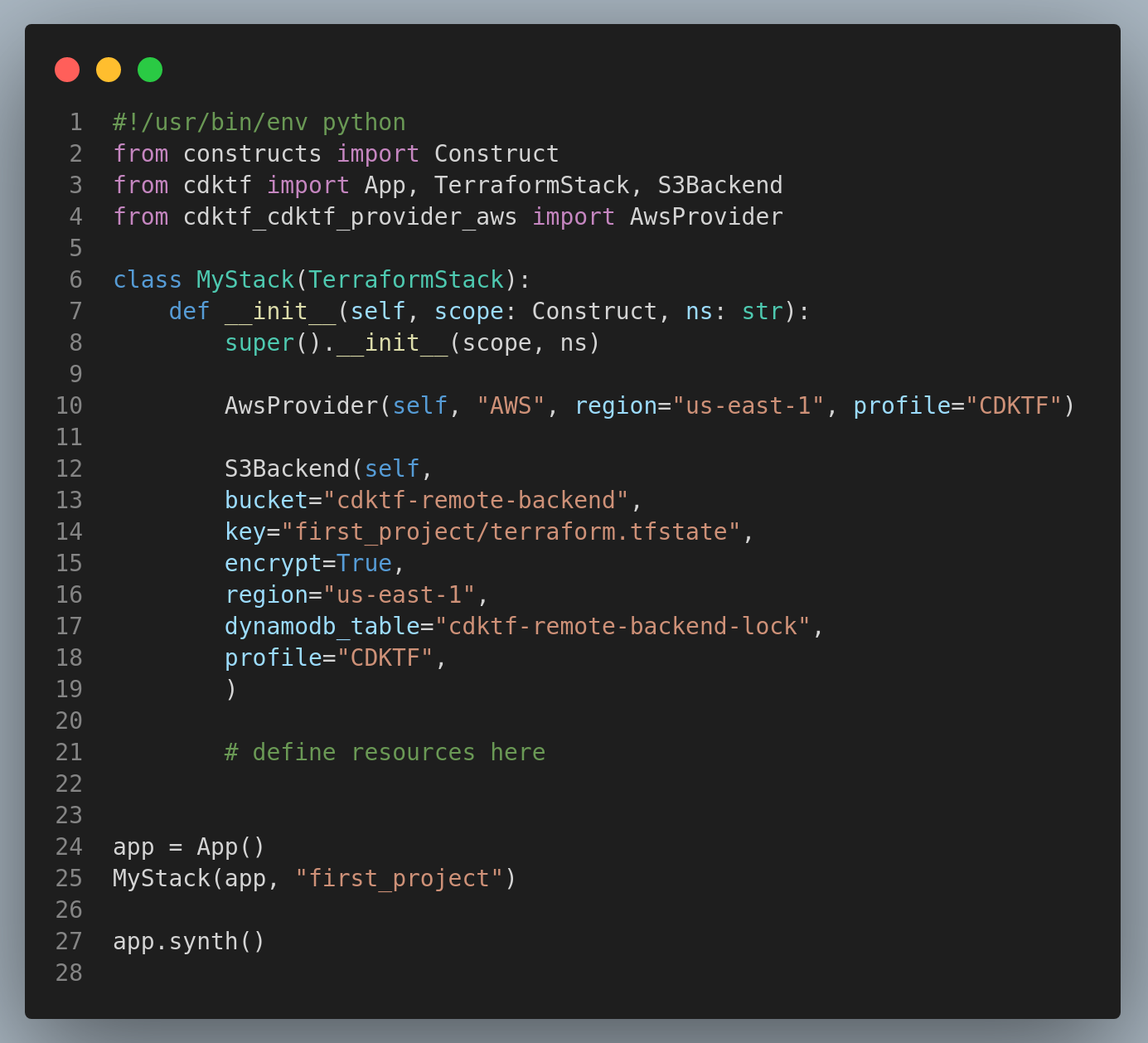
The final main.py file should look like this:
from constructs import Construct
from cdktf import App, TerraformStack, S3Backend
from cdktf_cdktf_provider_aws import AwsProvider
class MyStack(TerraformStack):
def __init__(self, scope: Construct, ns: str):
super().__init__(scope, ns)
AwsProvider(self, "AWS", region="us-east-1", profile="CDKTF")
S3Backend(self,
bucket="cdktf-remote-backend",
key="first_project/terraform.tfstate",
encrypt=True,
region="us-east-1",
dynamodb_table="cdktf-remote-backend-lock",
profile="CDKTF",
)
# define resources here
app = App()
MyStack(app, "first_project")
app.synth()
- Run
cdktf synthto generate the Terraform configuration files. The Terraform configuration files will be generated in thecdktf.outdirectory. Thesynthcommand will fail if the S3 bucket and DynamoDB table don’t exist.
cdktf synth
You have successfully configured the S3 Remote Backend. Let’s move on to the next section.
- To test the configuration of the S3 remote backend, follow the below steps to create an S3 bucket resource and deploy the stack.
- Import the S3 bucket library to the
main.pyfile:
from cdktf_cdktf_provider_aws import AwsProvider, s3
- Add the S3 bucket resource to the
MyStackclass:
my_bucket = s3.S3Bucket(self, "my_bucket",
bucket="Name-of-the-bucket",
)
-
Replace
Name-of-the-bucketwith the name of the bucket you want to create. Note, S3 bucket names must be unique across all existing bucket names in Amazon S3. -
Run
cdktf deployto deploy the stack and create the S3 bucket.
cdktf deploy

Note: if you get
Incomplete lock file information for providerswarning, you can either ignore it or you can runterraform providers lock -platform=linux_amd64from the project root directory to validate the lock file. For more information, refer to Terraform documentation.
Congratulations, you have successfully configured an S3 remote backend and created an S3 bucket using CDKTF. It’s time to take a break and stretch your legs.
Option 2: Create an S3 Bucket and DynamoDB Table for the S3 Remote Backend using CDKTF
For this option, we will take a different approach. We will create the S3 bucket and DynamoDB table using CDKTF and then configure the S3 remote backend to use the newly created resources. Follow the below steps to create the S3 bucket and DynamoDB table:
-
Open the project directory using your preferred IDE. If you are using VS Code,
cdinto the project folder and runcode .on the terminal to open the project directory using VS Code. -
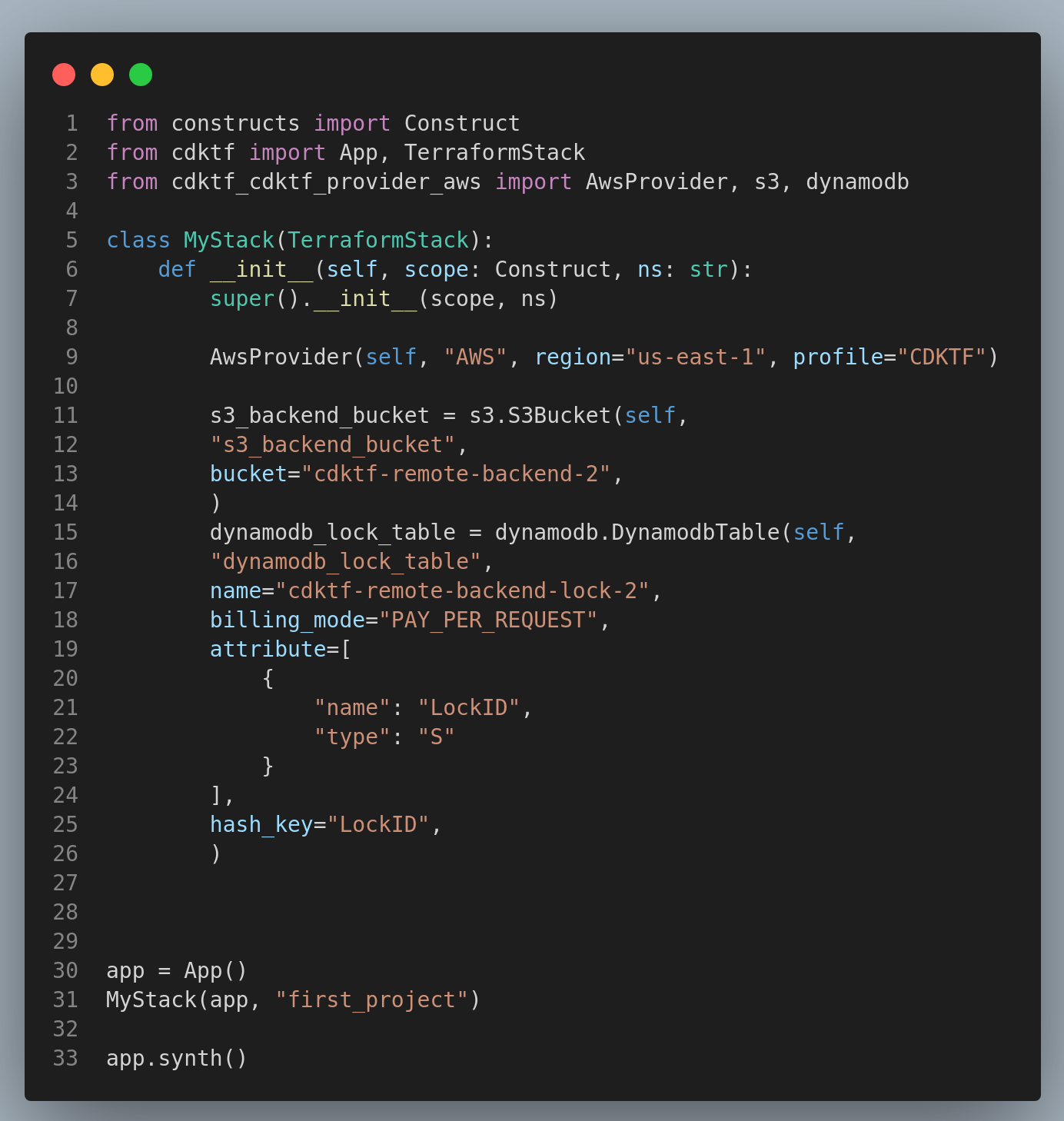
Navigate to the
main.pyfile and replace the default code with the following. This code creates an S3 bucket and DynamoDB table for the S3 remote backend.
from constructs import Construct
from cdktf import App, TerraformStack, S3Backend
from cdktf_cdktf_provider_aws import AwsProvider, s3, dynamodb
class MyStack(TerraformStack):
def __init__(self, scope: Construct, ns: str):
super().__init__(scope, ns)
AwsProvider(self, "AWS", region="us-east-1", profile="CDKTF")
# define resources here
s3_backend_bucket = s3.S3Bucket(self,
"s3_backend_bucket",
bucket="cdktf-remote-backend-2",
)
dynamodb_lock_table = dynamodb.DynamodbTable(self,
"dynamodb_lock_table",
name="cdktf-remote-backend-lock-2",
billing_mode="PAY_PER_REQUEST",
attribute=[
{
"name": "LockID",
"type": "S"
}
],
hash_key="LockID",
)
app = App()
MyStack(app, "first_project")
app.synth()
Note, if the S3 bucket and DynamoDB table already exist, an error will be thrown. The S3 bucket names must be globally unique across all existing bucket names in Amazon S3 and DynamoDB table names must be unique within an AWS account. If you get an error, you can change the bucket and table names to unique names.
- Run
cdktf deployto deploy the stack and create the S3 bucket and DynamoDB table.
cdktf deploy

Note: if you get
Incomplete lock file information for providerswarning, you can either ignore it or you can runterraform providers lock -platform=linux_amd64from the project root directory to validate the lock file.
- Now, we will configure the S3 remote backend to use the newly created S3 bucket and DynamoDB table. Open the
main.pyfile and replace the code with the following. This code configures the S3 remote backend to use the newly created S3 bucket and DynamoDB table. Make sure to replace thebucketanddynamodb_tablevalues with the names of the S3 bucket and DynamoDB table you created in the previous step.
from constructs import Construct
from cdktf import App, TerraformStack, S3Backend
from cdktf_cdktf_provider_aws import AwsProvider, s3, dynamodb
class MyStack(TerraformStack):
def __init__(self, scope: Construct, ns: str):
super().__init__(scope, ns)
AwsProvider(self, "AWS", region="us-east-1", profile="CDKTF")
#S3 Remote Backend
S3Backend(self,
bucket="cdktf-remote-backend-2",
key="first_project/terraform.tfstate",
encrypt=True,
region="us-east-1",
dynamodb_table="cdktf-remote-backend-lock-2",
profile="CDKTF",
)
# Resources
s3_backend_bucket = s3.S3Bucket(self, "s3_backend_bucket",
bucket="cdktf-remote-backend-2",
)
dynamodb_lock_table = dynamodb.DynamodbTable(self, "dynamodb_lock_table",
name="cdktf-remote-backend-lock-2",
billing_mode="PAY_PER_REQUEST",
attribute=[
{
"name": "LockID",
"type": "S"
}
],
hash_key="LockID",
)
app = App()
MyStack(app, "first_project")
app.synth()
- Run
cdktf synthto generate the Terraform configuration files. The Terraform configuration files will be generated in thecdktf.outdirectory.
cdktf synth
- To migrate the local state backend to an S3 remote backend, navigate to the
cdktf.out/stacks/first_projectdirectory and run the following command to start the migration process. Thefirst_projectis the name of the project. If you have named your project differently, navigate to thecdktf.out/stacks/<project_name>directory and run the command.
Note: before running this command, read Important Notes below
cd cdktf.out/stacks/first_project
terraform init --migrate-state
Important Notes:
When you run terraform init --migrate-state, Terraform prompts you to answer the following question:
Do you want to copy existing state to the new backend?
A. If you enter, yes to migrate the state file to the S3 backend, CDKTF will manage the S3 remote backend (S3 bucket and DynamoDB table) for you. Therefore, if you delete the stack, the S3 bucket and DynamoDB table will be vurnerable to deletion. Note, we can’t delete a non-empty S3 unless we add force_destroy=True to the S3 bucket configuration. This option is not recommended if you want to keep the S3 bucket and DynamoDB table, especially if you are using the S3 bucket and DynamoDB table as a remote backend for other Terraform projects. But, if you are just experimenting with CDKTF, this option is fine.
B. If you enter no, to migrate the state file to the S3 backend, CDKTF will not manage the S3 bucket and DynamoDB table. If you delete the stack, the S3 bucket and DynamoDB table will not be deleted and you will have to manually delete the S3 bucket and DynamoDB table. Moreover, you will also need to remove the S3 bucket and DynamoDB table constructs from the main.py file.
To read more about initializing remote backend manually, refer to the Terraform documentation.
The below terminal recording demonstrates the steps above. In the recording, I have shown the error message that you may get if you attempt to run cdktf deploy prior to reconfiguring from local backend to an S3 remote backend.
I have entered yes to migrate the state file to the S3 remote backend and let the CDKTF manage the S3 bucket and DynamoDB table.

- Run
cdktf difffrom the project root directory to compare the current state of the stack with the desired state of the stack. The output should be empty, which means there are no changes to be made and the state file is up to date.
cdktf diff
Note: you have to be in the project root directory to run
cdktf diff.
Great! You have successfully migrated the local state backend to an S3 remote backend. Way to go, you have achieved another milestone! 🎉🎉🎉
Step 4: Learn How to Use Construct Hub and AWS Provider Submodules
Prior to digging into the AWS provider, let’s first understand most commonly used terms in the CDKTF documentation:
-
Submodules is a collection of related resources. For example, the
s3.S3Bucketconstruct is part of thes3submodule. Thes3.S3Bucketconstruct creates an S3 bucket. Thes3submodule contains other constructs such ass3.S3BucketPolicy,s3.S3BucketAcl,s3.S3BucketObject, etc. -
Construct is another important term to understand. A construct is a class that represents a Terraform resource, data source, or provider. The
s3submodule contains constructs that represent S3 constructs, classes and struts. -
Stack is a collection of constructs. The
MyStackclass in themain.pyfile is a stack. TheMyStackclass contains constructs that represent S3 constructs, classes and struts.
Scenario 1: S3 Bucket
Let’s say we would like to create an S3 but we don’t know which construct to use. Let’s head to the Python Construct hub for the AWS provider and follow the steps below:
- From the left hand side and under Documentation, click on Choose Submodule.
- In the search box, type in s3 and then click on the result, which is s3.
- Under Submodule:s3, you will see a list of Constructs and Struts. Click on S3Bucket
- To create an S3 bucket, you will import the s3 class as shown under
Initializers. - The construct to use is
s3.S3Bucket. - We need to find the required configurations for the
s3.S3Bucketconstruct. Scan the page and look for configurations markedRequired. In this case, S3 bucket does not have any required configuration, not even a name. If you leave the name argument empty, the S3 bucket will be created with a random name. We can specify a name for the S3 bucket and other configurations, but this is not required.
We have to distinguish between required and optional configurations. Required configurations must be specified when creating a resource. Optional configurations can be specified when creating a resource.
This is the code snippet for creating an S3 bucket with minimal configurations:
my_3bucket= s3.S3Bucket(self, "s3_bucket")
Note: if you leave the name argument empty, the S3 bucket will be created with a random name.
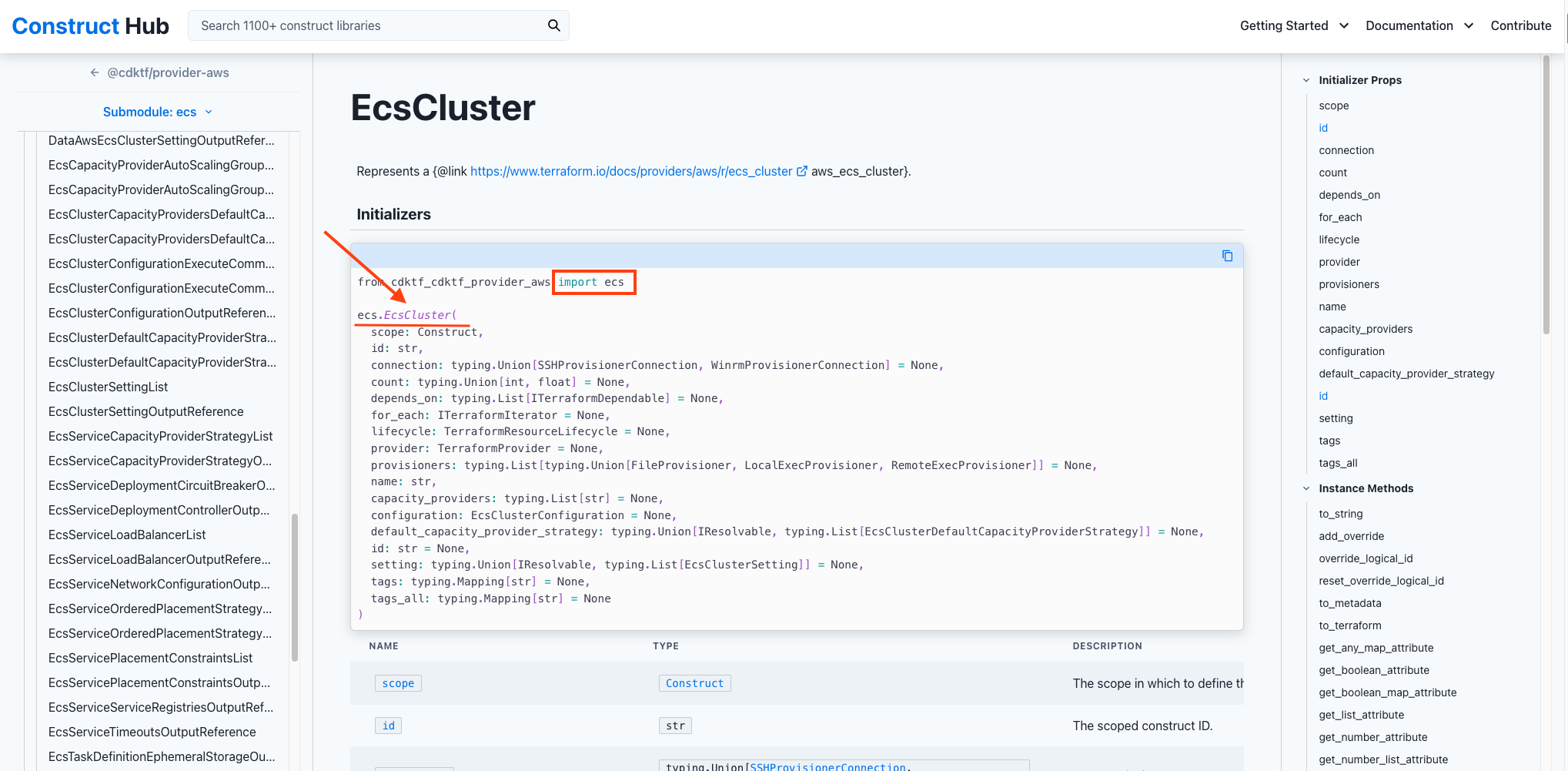
Scenario 2: ECS Cluster
This time let’s say we would like to create an ECS cluster. Let’s head to the Python Construct hub for the AWS provider and follow the steps below:
- From the left hand side and under Documentation, click on Choose Submodule.
- In the search box, type in ecs and then click on the result, which is ecs.
- Under Submodule:ecs, you will see a list of Constructs and Struts. Click on EcsCluster
- To create an ECS cluster, you will import ecs class as shown under
Initializers. - The construct to use is
ecs.EcsClusteras shown below. - We need to find the required configurations for the
ecs.EcsClusterconstruct. The minimum required configurations to create an ECS cluster is just thenameof the cluster. But, we can also specify other configurations such as,capacity_providers,default_capacity_provider_strategy,configuration, etc.
my_ecs_cluster = ecs.EcsCluster(self, "my_ecs_cluster",
name = "My_Cluster"
)
CDKTF Commands:
There are several CDKTF commands that we need to be familiar with. The below table shows the commands, their descriptions and the corresponding Terraform commands.
| Commands | Description | Aliases |
|---|---|---|
| cdktf init | Create a new cdktf project from a template. | |
| cdktf get | Generate CDK Constructs for Terraform providers and modules. | |
| cdktf convert | Converts a single file of HCL configuration to CDK for Terraform. Takes the file to be converted on stdin. | |
| cdktf deploy | Deploy the given stacks | [aliases: apply] |
| cdktf destroy | Destroy the given stacks | |
| cdktf diff | Perform a diff (terraform plan) for the given stack | [aliases: plan] |
| cdktf list | List stacks in app. | |
| cdktf login | Retrieves an API token to connect to Terraform Cloud or Terraform Enterprise. | |
| cdktf synth | Synthesizes Terraform code for the given app in a directory. | [aliases: synthesize] |
| cdktf watch | [experimental] Watch for file changes and automatically trigger a deploy | |
| cdktf output | Prints the output of stacks | [aliases: outputs] |
| cdktf debug | Get debug information about the current project and environment | |
| cdktf provider | A set of subcommands that facilitates provider management | |
| cdktf completion | generate completion script |
To find out more about the cdktf commands, run cdktf [command] --help and replace [command] with the command you want to learn more about.
For example, to learn more about the cdktf deploy command, run cdktf deploy --help.
Step 5: Deploying a Lambda Function URL using CDKTF
CDKTF is a great tool to provision AWS resources. We have already created an S3 bucket and DynamoDB table in the previous section. In this section, I will show you how to create a Lambda function using CDKTF with function url enabled. The lambda will host a simple static web page, and well configure the function url as an output. The process requires creating an IAM role and attaching a policy to the role. I will also introduce you to multiple concepts in CDKTF.
In this section, I will cover the following topics:
- How to create an IAM role for Lambda function
- How to attach a policy to the IAM role
- How to create a Lambda function
- How to enable function url for the Lambda function
- How to package a Lambda function from a local directory and python file
- How to create an output for the Lambda function url
Buckle up, we are going to learn a lot in this section! 🚀🚀🚀
Follow the steps below to deploy a Lambda function URL using CDKTF:
-
Firstly, let’s keep out project organized and create a new directory called
lambdain the root directory of the project. This is where we will store our Lambda function code. -
Create a new file called
lambda_function.pyin thelambdadirectory. -
Copy the
lambda_function.pycode from my GitHub repository and paste it into thelambda_function.pyfile. -
I will go over the
main.pycode and the finalmain.pyfile will provided at the end of the section.
- In the
main.pyfile, import theTerraformOutput,TerraformAssetandAssetTypeclasses from thecdktfmodule. Assets construct is introduced in CDK for Terraform v0.4+ and is used to package a local directory and python file into a zip file. TheTerraformOutputconstruct is used to create an output for the Lambda function url. TheAssetTypeis used to specify the type of asset.
The final import statements should look like this:
from constructs import Construct
from cdktf import App, TerraformStack, S3Backend, TerraformOutput, TerraformAsset, AssetType
from cdktf_cdktf_provider_aws import AwsProvider, s3, dynamodb, iam, lambdafunction
import os
import os.path as Path
Note, we have imported
osandos.path as Pathmodules. We will use these modules to get the current working directory and to join the path to the lambda directory.
- The
TerraformAssetconstruct requires apathargument. Thepathargument is the path to the directory or file that you want to package. In this case, we will use theosmodule to get the current working directory and then join the path to thelambdadirectory. TheAssetType.ARCHIVEis to specify that the asset is an archive. The finalpathargument should look like this:
asset = TerraformAsset(self, "lambda_file",
path = Path.join(os.getcwd(), "lambda"),
type = AssetType.ARCHIVE,
)
- Creating a Lambda function requires creating an IAM role. Therefore, we will create an IAM role first. We will also attach the
AWSLambdaBasicExecutionRoleAWS managed policy to the IAM role. This policy allows the Lambda function to write logs to CloudWatch. Refer to AWS documentation for more information about the AWSLambdaBasicExecutionRole policy.
The assume_role_policy argument is the policy that grants permission to assume the IAM role, which requires a JSON string. The JSON string is the policy document that grants permission to assume the IAM role. The final snippet of code should look like this:
lambda_role = iam.IamRole(self, "lambda_role",
name="my-lambda-url-role",
managed_policy_arns=[
"arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
],
assume_role_policy="""{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}""",
)
- Now, we are ready to create a lambda function. The
handlerconfiguration is the name of the python file that contains the lambda function. Theruntimeprovides a language-specific environment that runs in an execution environment. Thesource_code_hashargument is the hash of the file that contains the lambda function. Thesource_code_hashargument is required to trigger a new deployment when the lambda function code changes. Thefilenameargument is the path to the file that contains the lambda function.
The final snippet of code should look like this:
my_lambda = lambdafunction.LambdaFunction(self, "my_lambda",
function_name="my-lambda-url",
handler="lambda_function.lambda_handler",
role=lambda_role.arn,
runtime="python3.9",
source_code_hash = asset.asset_hash,
filename=asset.path,
)
- We need to enable function url for the lambda function and define an
authorization_typefor the function url. Theauthorization_typeargument is the type of authorization that is used to invoke the function url. Theauthorization_typeargument can be set toNONEorAWS_IAM. The final snippet of code should look like this:
my_lambda_url = lambdafunction.LambdaFunctionUrl(self, "my_lambda_url",
function_name=my_lambda.function_name,
authorization_type="NONE",
)
- Finally, we need to create an output for the Lambda function url. The
valueargument is the value of the output. Thevalueargument can be a string, number, boolean, or a list. The final snippet of code should look like this:
TerraformOutput(self, "lambda_url",
value=my_lambda_url.invoke_url,
)
The final main.py code should look like this:
from constructs import Construct
from cdktf import App, TerraformStack, S3Backend, TerraformOutput, TerraformAsset, AssetType
from cdktf_cdktf_provider_aws import AwsProvider, s3, dynamodb, iam, lambdafunction
import os
import os.path as Path
class MyStack(TerraformStack):
def __init__(self, scope: Construct, ns: str):
super().__init__(scope, ns)
AwsProvider(self, "AWS", region="us-east-1", profile="CDKTF")
#S3 Remote Backend
S3Backend(self,
bucket="cdktf-remote-backend-2",
key="first_project/terraform.tfstate",
encrypt=True,
region="us-east-1",
dynamodb_table="cdktf-remote-backend-lock-2",
profile="CDKTF",
)
# Resources
s3_backend_bucket = s3.S3Bucket(self, "s3_backend_bucket",
bucket="cdktf-remote-backend-2",
)
dynamodb_lock_table = dynamodb.DynamodbTable(self, "dynamodb_lock_table",
name="cdktf-remote-backend-lock-2",
billing_mode="PAY_PER_REQUEST",
attribute=[
{
"name": "LockID",
"type": "S"
}
],
hash_key="LockID",
)
# Asset for Lambda Function
asset = TerraformAsset(self, "lambda_file",
path = Path.join(os.getcwd(), "lambda"),
type = AssetType.ARCHIVE,
)
# IAM Role for Lambda Function
lambda_role = iam.IamRole(self, "lambda_role",
name="my-lambda-url-role",
managed_policy_arns=[
"arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
],
assume_role_policy="""{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}""",
)
# Lambda Function
my_lambda = lambdafunction.LambdaFunction(self, "my_lambda",
function_name="my-lambda-url",
handler="lambda_function.lambda_handler",
role=lambda_role.arn,
runtime="python3.9",
source_code_hash = asset.asset_hash,
filename=asset.path,
)
# Lambda Function Url
my_lambda_url = lambdafunction.LambdaFunctionUrl(self, "my_lambda_url",
function_name=my_lambda.function_name,
authorization_type="NONE",
)
# Outputs for Lambda Function Url
TerraformOutput(self, "lambda_url",
value=my_lambda_url.function_url,
)
app = App()
MyStack(app, "first_project")
app.synth()
- Run
cdktf deployto deploy the stack.
cdktf deploy
Note: you can also run
cdktf deploy --auto-approveto deploy the stack without confirmation. However, I would suggest to refrain from using this option in production unless you are absolutely sure that you want to deploy the stack without confirmation.
Finally, grab the lambda_url output and paste it in your browser. If you see the dancing bananas, then you have successfully deployed your first lambda function using CDKTF.
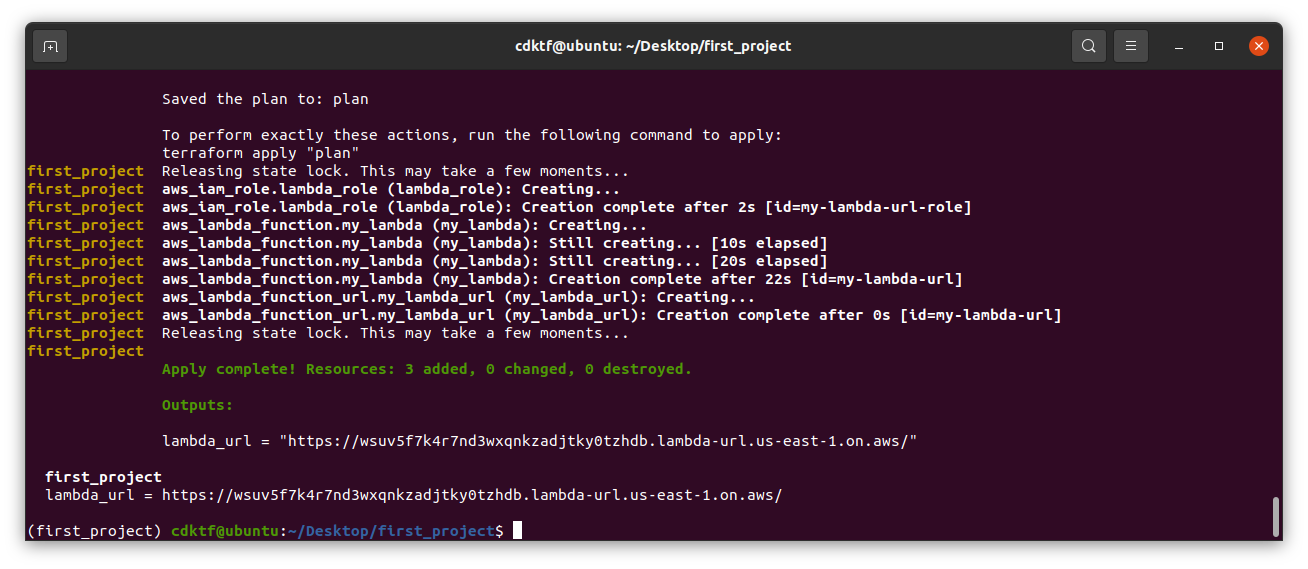
Congratulations! You have successfully deployed a lambda function with a function url using CDKTF. I’m sure you feel like you are on top of the world right now. Well done!
To delete the stack, we need to follow the below steps:
Note, we chose to allow CDKTF to manage the remote backend. This means that CDKTF will delete the remote backend (the S3 bucket and DynamoDB Table) when we delete the stack. There are many methods to delete the stack, but I find the below method to be the easiest. Let’s go through the steps:
A. Add force_destroy=True to the s3_backend_bucket configurations. The S3 bucket cannot be deleted if it is not empty. This is the reason why we need to add force_destroy=True.
s3_backend_bucket = s3.S3Bucket(self, "s3_backend_bucket",
bucket="cdktf-remote-backend-2",
force_destroy=True
)
B. Run cdktf deploy to update the S3 bucket configurations:
cdktf deploy
C. Run cdktf destroy to delete the entire stack:
cdktf destroy
Note: after running
cdktf destroy, you will get an error message sayingfailed to retrieve lock info. This is expected due to the fact the dynamodb table is deleted. You can ignore this error message.
Conclusion
In this tutorial, we have learned how to properly install and configure CDKTF, how to migrate from a local backend to an S3 remote backend. We have also learned how to deploy a lambda function with a function url using CDKTF. We have also briefly learned how to read and utilize the CDKTF documentations from the Construct Hub.
The most important thing to remember is that CDKTF is still in its early stages. There are many features that are not yet available. However, I am confident that CDKTF will be a great tool for managing Terraform stacks in the future.
Congratulations on completing this tutorial and overcoming several challenges. You have achieved many learning milestones. I hope this tutorial added value to your learning journey. Thank you for reading!
Omar A Omar
Site Reliability Engineer